



What Is an AI Factory? And Why 800G/1.6T Optics Are Its Backbone

The Shift from Data Centers to AI Factories
Something has quietly changed in the way infrastructure is being built. Not long ago, a data center was mostly about storage, virtualization, and handling user requests. Now it feels different. The workloads are heavier, more continuous, and in many cases not even tied to direct user actions. AI systems run in the background, generating, reasoning, iterating, sometimes looping through tasks that never really “end” in the traditional sense.
The concept of the “AI factory” is no longer just a buzzword; it is increasingly becoming a reality. Data is entered into large models for processing and continuous output generation. This system bears a closer resemblance to an industrial system than to an IT architecture. Just as NVIDIA intended when it launched the Rubin platform, the goal is to complete this architectural revolution. The challenges we face today extend beyond the hardware's capabilities. At the infrastructure level, we must consider how to build a system capable of supporting large-scale AI production while reducing inference costs and improving deployment predictability.
Once infrastructure starts behaving like a factory, the pressure spreads across the entire stack. Compute is only one part of it. Storage, memory, scheduling, orchestration, and, especially, networking all begin to matter in different ways. You don't just need performance—you need consistency under load, and the ability to scale without everything becoming fragile.
Inside the Rubin Platform: A Different Kind of System Design
Looking at Rubin more closely, it doesn't really follow the old incremental upgrade pattern. It feels more like a reset. Instead of improving isolated components, the platform brings multiple layers together and optimizes them as a whole. The Vera CPU, Rubin GPU, NVLink 6, ConnectX-9 SuperNIC, BlueField-4 DPU, and Spectrum-6 Ethernet are all part of that design.
This kind of coordination changes how systems behave. For example, MoE training workloads now require significantly fewer GPUs compared to previous generations, but that doesn't reduce overall activity. It just redistributes it. Inference becomes more frequent, models become more complex, and workloads stretch across longer sequences. The system ends up moving more data, not less.
The NVL72 rack-scale system is a good illustration. Packing dozens of GPUs into a tightly integrated unit sounds efficient—and it is—, but it also creates dense communication patterns inside the rack. Data doesn't just flow up and down anymore. It constantly moves laterally across GPUs, memory pools, and accelerators. That internal pressure eventually spills out into the broader network.
Why AI Factories Stress the Network in a Different Way
The network within an AI Factory is different enough that older assumptions start to break down. It's not just that there's a higher demand for bandwidth. The traffic pattern changes. East-west traffic is the main thing, and it usually stays high rather than fluctuating. GPUs are constantly exchanging data, especially in distributed training and multi-step inference scenarios. Latency becomes more visible, not in theory but in actual performance.
At the same time, the underlying technologies are moving fast. NVLink 6, for instance, pushes GPU-to-GPU bandwidth to a level where each device can handle several terabytes per second. Inside a single rack, aggregate bandwidth climbs to hundreds of terabytes per second. That’s not a small step up—it's a different scale entirely.
In the field of Ethernet, NVIDIA Spectrum-X is transforming the way AI networks are constructed. Instead of treating Ethernet as a general-purpose fabric, it is being tuned specifically for AI workloads. The efficiency improvements are evident, but what stands out more is the stability under sustained load. AI clusters don’t idle much, so uptime and consistency start to matter just as much as peak performance.
There's also BlueField-4 in the mix, which shifts some data-handling and security functions away from the CPU. It doesn't always get as much attention, but in large-scale deployments, it helps keep things manageable. And with the move toward AI-native storage, where inference context can be reused across sessions, the overall system starts to look less like a bunch of servers and more like a coordinated pipeline.
All of this leads to a simple observation. The network is more than just a connector between computer nodes these days. It becomes part of the computation process itself. And once that happens, the limitations of older designs—especially those built on 400G assumptions—become more apparent.
400G vs 800G vs 1.6T: What Actually Changes and Why It Matters
Moving from 400G to 800G, or even 1.6T, might seem like a straightforward speed upgrade. In reality, the differences run deeper than bandwidth numbers.
400G still has its place. It's widely deployed, relatively mature, and works well in environments with predictable traffic patterns or where traffic isn't constantly saturated. For traditional cloud workloads, or even smaller AI clusters, it can still deliver a reasonable balance between cost and performance. The issue is that AI Factories don’t behave like that anymore. Traffic is denser, more continuous, and less forgiving when bottlenecks appear.
800G starts to make more sense when switch architectures shift toward 200G SerDes. Instead of combining a bunch of slower links, you get a clearer connection between the switch's capacity and the optical interfaces. This can make things simpler in some situations, but more importantly, it boosts overall productivity without needing more space. In large GPU clusters, that kind of efficiency adds up quickly.
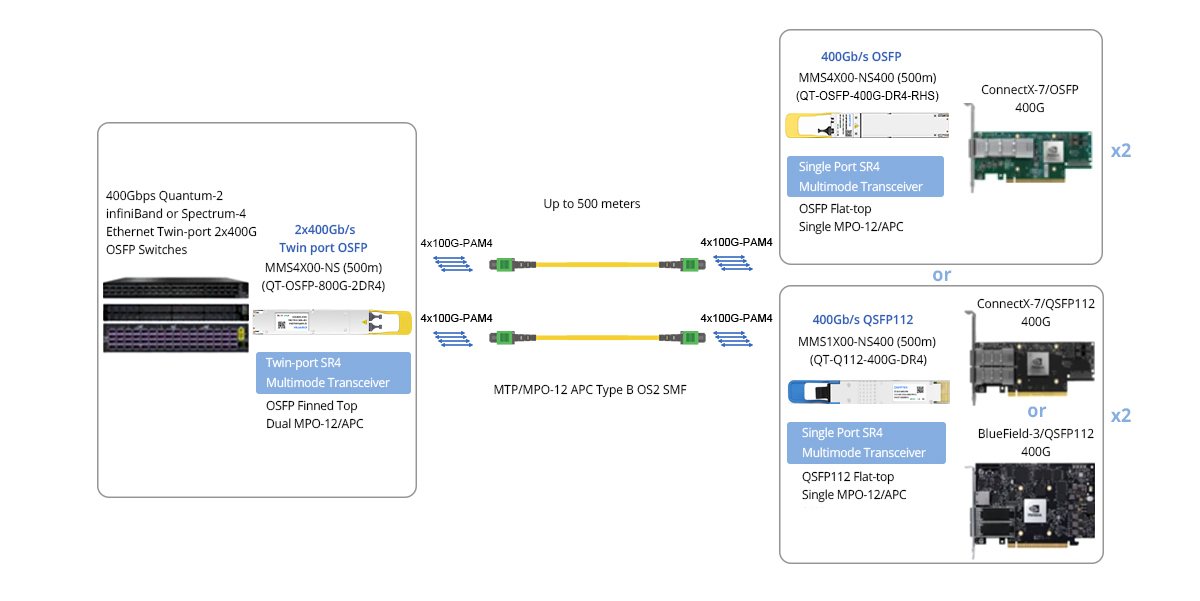
The 800G NVIDIA/Mellanox MMS4X00-NS is compatible with Quantum-2 and Spectrum-4 air-cooled switches, liquid-cooled and DGX-H100 systems, ConnectX-7 and BlueField-3 DPUs.
Then there's the 1.6T, which doesn't really feel like an upgrade, but more like they're getting ready for the next step. It allows for higher port density, meaning fewer switches are needed to achieve the same scale. Power efficiency per bit also improves, which is important as energy consumption starts to limit expansion. In very large AI deployments—think tens or hundreds of thousands of GPUs—the difference between scaling with 800G and jumping to 1.6T isn't just technical; it also affects cost models and physical layout.

The 1.6T NVIDIA/Mellanox MMS4A00 is compatible with Quantum-3 air-cooled and liquid-cooled switches.
In practice, these options don’t replace each other overnight. They usually get along. 400G might still be used at the edge or in less demanding segments. 800G is becoming the main fabric for current AI clusters. 1.6T starts appearing in new builds or in parts of the network where density and efficiency matter most. The "best" choice depends less on the spec sheet and more on how the system is expected to change over time.
This is also where solution providers can help. QSFPTEK, for example, has 800G and 1.6T optical modules, as well as ways to set them up that work well for AI data centers. The focus is on how these tiers fit into real architectures, not just on speed tiers. In some cases, mixing generations within the same network can lead to better results than forcing a full upgrade all at once.
Looking Ahead: Why 1.6T Is Closer Than It Seems
Although 800G is becoming more common, it doesn't feel like it's the final version. AI workloads are growing, but not always in the same ways. Models are getting bigger, but they're also becoming more interactive. Inference is no longer a simple request-response cycle. It can involve multiple steps, external tools, and longer context windows. All of that increases the amount of data moving through the system.
There's also the question of scale beyond a single location. Some of the newer architectures are designed to connect multiple data centers into a single logical environment. That adds distance into the equation, along with new latency and synchronization challenges.
1.6T optics fit into this picture quite naturally. They don't solve everything, but they remove some of the immediate constraints around bandwidth and density. Instead of constantly working around limits, network design becomes a bit more flexible again. That alone can simplify large deployments.
Conclusion
QSFPTEK has been preparing for this kind of scenario with its 1.6T portfolio, as well as other AI infrastructure solutions. It's not about always going as fast as you can. It's more about having the option ready when the network reaches a point where incremental upgrades aren't enough.
In the end, the idea of an AI Factory brings everything back to flow—how data moves, how fast it moves, and how reliably it gets from one place to another. Optical modules don't usually get much attention, but they sit right in that path. And as the rest of the system continues to scale, their role becomes harder to ignore.





share

